SSE
简介
服务器向客户端推送数据,有很多解决方案。除了“轮询” 和 WebSocket,HTML 5 还提供了 Server-Sent Events(以下简称 SSE)。
一般来说,HTTP 协议只能客户端向服务器发起请求,服务器不能主动向客户端推送。但是有一种特殊情况,就是服务器向客户端声明,接下来要发送的是流信息(streaming)。也就是说,发送的不是一次性的数据包,而是一个数据流,会连续不断地发送过来。这时,客户端不会关闭连接,会一直等着服务器发过来的新的数据流。本质上,这种通信就是以流信息的方式,完成一次用时很长的下载。
SSE 就是利用这种机制,使用流信息向浏览器推送信息。
与 WebSocket 的比较
SSE 与 WebSocket 作用相似,都是建立浏览器与服务器之间的通信渠道,然后服务器向浏览器推送信息。
总体来说,WebSocket 更强大和灵活。因为它是全双工通道,可以双向通信;SSE 是单向通道,只能服务器向浏览器发送,因为 streaming 本质上就是下载。如果浏览器向服务器发送信息,就变成了另一次 HTTP 请求。
但是,SSE 也有自己的优点。
- SSE 使用 HTTP 协议,现有的服务器软件都支持。WebSocket 是一个独立协议。
- SSE 属于轻量级,使用简单;WebSocket 协议相对复杂。
- SSE 默认支持断线重连,WebSocket 需要自己实现断线重连。
- SSE 一般只用来传送文本,二进制数据需要编码后传送,WebSocket 默认支持传送二进制数据。
- SSE 支持自定义发送的消息类型。
因此,两者各有特点,适合不同的场合。
浏览器端的 API
EventSource
SSE 的客户端 API 部署在EventSource对象上。下面的代码可以检测浏览器是否支持 SSE。
if ('EventSource' in window) {
// ...
}使用 SSE 时,浏览器首先生成一个EventSource实例,向服务器发起连接。
var source = new EventSource(url, { withCredentials: true });上面的url可以与当前网址同域,也可以跨域。跨域时,可以指定第二个参数,打开withCredentials属性,表示是否一起发送 Cookie。
readyState 属性
EventSource实例的readyState属性,表明连接的当前状态。该属性只读,可以取以下值。
0:EventSource.CONNECTING,表示连接还未建立,或者断线正在重连。 1:EventSource.OPEN,表示连接已经建立,可以接受数据。 2:EventSource.CLOSED,表示连接已断,且不会重连。
var source = new EventSource(url);
console.log(source.readyState);url 属性
EventSource实例的url属性返回连接的网址,该属性只读。
withCredentials 属性
EventSource实例的withCredentials属性返回一个布尔值,表示当前实例是否开启 CORS 的withCredentials。该属性只读,默认是false。
onopen 属性
连接一旦建立,就会触发open事件,可以在onopen属性定义回调函数。
source.onopen = function (event) {
// ...
};
// 另一种写法
source.addEventListener('open', function (event) {
// ...
}, false);onmessage 属性
客户端收到服务器发来的数据,就会触发message事件,可以在onmessage属性定义回调函数。
source.onmessage = function (event) {
var data = event.data;
var origin = event.origin;
var lastEventId = event.lastEventId;
// handle message
};
// 另一种写法
source.addEventListener('message', function (event) {
var data = event.data;
var origin = event.origin;
var lastEventId = event.lastEventId;
// handle message
}, false);上面代码中,参数对象event有如下属性。 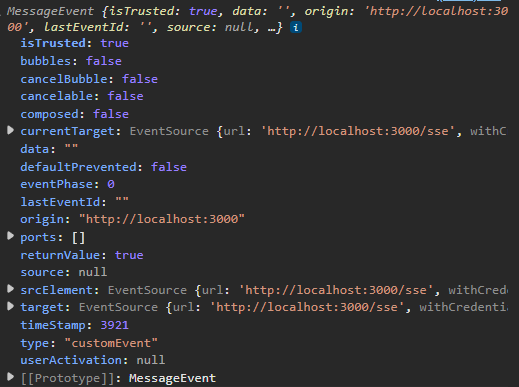
data:服务器端传回的数据(文本格式)。 origin:服务器 URL 的域名部分,即协议、域名和端口,表示消息的来源。 lastEventId:数据的编号,由服务器端发送。如果没有编号,这个属性为空。
onerror 属性
如果发生通信错误(比如连接中断),就会触发error事件,可以在onerror属性定义回调函数。
source.onerror = function (event) {
// handle error event
};
// 另一种写法
source.addEventListener('error', function (event) {
// handle error event
}, false);自定义事件
默认情况下,服务器发来的数据,总是触发浏览器EventSource实例的message事件。开发者还可以自定义 SSE 事件,这种情况下,发送回来的数据不会触发message事件。
source.addEventListener('foo', function (event) {
var data = event.data;
var origin = event.origin;
var lastEventId = event.lastEventId;
// handle message
}, false);上面代码中,浏览器对 SSE 的foo事件进行监听。
close() 方法
close方法用于关闭 SSE 连接。 source.close();
服务器端实现
数据格式概述
服务器向浏览器发送的 SSE 数据,必须是 UTF-8 编码的文本,具有如下的 HTTP 头信息。
Content-Type: text/event-stream
Cache-Control: no-cache
Connection: keep-alive每一次发送的信息,都由若干个message组成,每个message之间用\n\n分隔。每个message内部由若干行组成,每一行都是形如[field]: value\n的格式。此外,还可以有冒号开头的行,表示注释。通常,服务器每隔一段时间就会向浏览器发送一个注释,保持连接不中断。
this is a test stream\n\n
data: some text\n\n
data: another message\n
data: with two lines \n\ndata 字段
数据内容用data字段表示,结尾用\n\n标识。
data: message\n\n
如果数据很长,可以分成多行,最后一行用\n\n结尾,前面行都用\n结尾。
data: begin message\ndata: continue message\n\n
下面是两种发送 JSON 数据的例子。
app.get('/sse', (req, res) => {
res.header('Content-Type', 'text/event-stream')
res.header('Cache-Control', 'no-cache')
res.header('Connection', 'keep-alive')
const content = JSON.stringify({
foo: 'bar',
baz: 555
})
let timer = setInterval(() => {
// 第一种:直接返回 stringify 的字符串加 \n\n
// res.write(`data: ${content}\n\n`);
// 第二种,多行地,拼接,结尾\n\n
res.write(`data: {\n`);
res.write(`data: "foo": "bar",\n`);
res.write(`data: "baz": 555\n`);
res.write(`data: }\n\n`);
}, 1000);
res.on('close', () => {
clearInterval(timer)
})
})id 字段
数据标识符用id字段表示,相当于每一条数据的编号。
id: msg1\n
data: message\n\n浏览器用lastEventId属性读取这个值。一旦连接断线,浏览器会发送一个 HTTP 头,里面包含一个特殊的Last-Event-ID头信息,将这个值发送回来,用来帮助服务器端重建连接。因此,这个头信息可以被视为一种同步机制,支持断点续传。
下面的例子使用文本字符串的索引作为 id 标识,实现了重连后继续之前的文本推送。
app.get('/sse', (req, res) => {
res.header('Content-Type', 'text/event-stream')
res.header('Cache-Control', 'no-cache')
res.header('Connection', 'keep-alive')
const content = fs.readFileSync(path.join(__dirname, '/data.txt'), 'utf-8').split('')
// 获取客户端传来的 Last-Event-ID
const lastEventId = req.headers['last-event-id'];
let startIndex = 0;
if (lastEventId) {
const lastId = parseInt(lastEventId, 10);
if (!isNaN(lastId)) {
startIndex = lastId + 1; // 从下一个字符开始
}
}
console.log('starting from index:', startIndex);
let cur = startIndex;
let timer = setInterval(() => {
res.write(`event: customEvent\n`)
res.write(`id: ${cur}\n`)
res.write(`data: ${content[cur]}\n\n`);
cur++;
if (cur >= content.length) {
clearInterval(timer);
}
}, 100);
res.on('close', () => {
clearInterval(timer)
})
})event 字段
event字段表示自定义的事件类型,默认是message事件。浏览器可以用addEventListener()监听该事件。
event: foo\n
data: a foo event\n\n ---> 第一条
data: an unnamed event\n\n ---> 第二条
event: bar\n
data: a bar event\n\n ---> 第三条上面的代码创造了三条信息。第一条的名字是foo,触发浏览器的foo事件;第二条未取名,表示默认类型message事件;第三条是bar,触发浏览器的bar事件。
下面是另一个例子。
event: userconnect
data: {"username": "bobby", "time": "02:33:48"}
event: usermessage
data: {"username": "bobby", "time": "02:34:11", "text": "Hi everyone."}
event: userdisconnect
data: {"username": "bobby", "time": "02:34:23"}
event: usermessage
data: {"username": "sean", "time": "02:34:36", "text": "Bye, bobby."}retry 字段
服务器可以用retry字段,指定浏览器重新发起SSE连接的时间间隔。现在主流浏览器通常默认是 3000 毫秒重连。
retry: 10000\n 两种情况会导致浏览器重新发起连接:一种是连接断开后指定的时间间隔到期,二是由于网络错误等原因,导致连接出错。
进一步分析
关于连接数的限制
上文中,我们使用 EventSource - Web API | MDN来实现 SSE。对于 EventSource文档里是这样描述的:
一个
EventSource实例会对HTTP服务器开启一个持久化的连接,以text/event-stream格式发送事件,此连接会一直保持开启直到通过调用.close()关闭。
并且有一段警告, 描述了浏览器针对 SSE 连接数的==限制==。6 in http 1
当不使用 HTTP/2时,服务器发送事件(SSE)受到打开连接数的限制,这个限制是_对于浏览器_的,并且设置为非常低的数字(6),打开多个选项卡时可能会特别痛苦。在 Chrome 和 Firefox 中,这个问题已被标记为“不会修复”。这个限制是每个浏览器和域名的,这意味着你可以在所有标签页中打开 6 个 SSE 连接到
www.example1.com,以及另外 6 个 SSE 连接到www.example2.com(来源:Stackoverflow)。当使用 HTTP/2 时,最大并发 HTTP 流的数量是由服务器和客户端协商的(默认为 100)。
大模型对话中的 SSE ?
这是我们 new EventSource(url) 时,浏览器发出的请求。 可以看到方法为 GET,类型为 eventsource
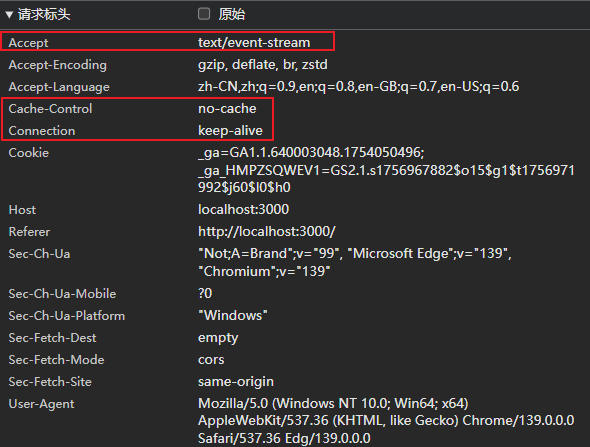
这是我使用 Qwen 进行一次对话时,浏览器发出的一个流式响应的请求 可以看到方法为 POST,类型为 fetch。
当发起下一次对话时,会新起一个这样的连接。
我还查看了 ChatGPT,也是通过POST + fetch 实现。 
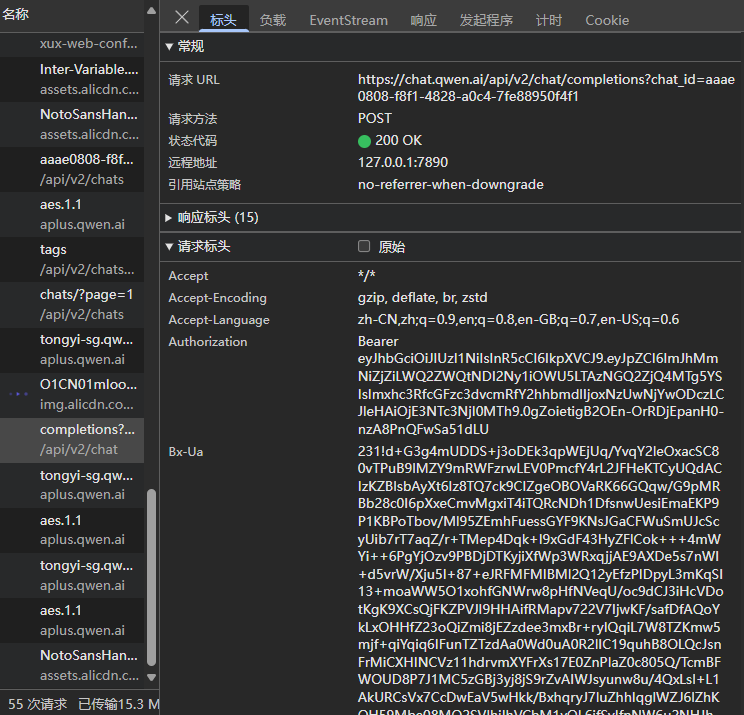
🔴 仔细查看这个请求头和响应头,请求头中,除了一些自定义的 xxxToken 之类的头,好像也没有特别的。此外,由于是 POST 请求,还把我问的 请你说说定军山战役给放在请求体里了,还有一些模型信息。 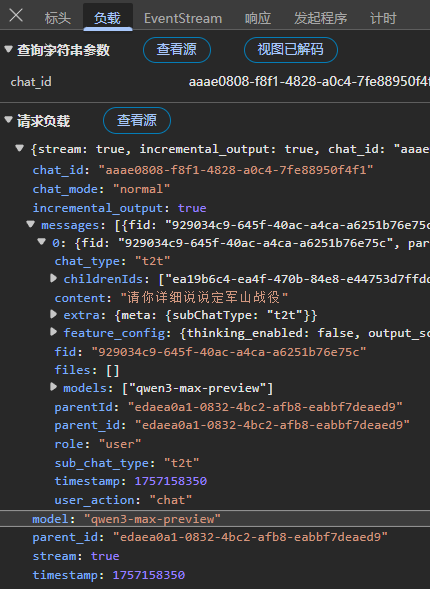
POST + Fetch 实现 SSE ?
那么如何用 post + fetch 实现 SSE 呢 ?我怎么感觉直接接口改为 post,服务端响应头还是 text/event-stream , 持续的 res.write() 应该就行?先不考虑什么关闭连接之类的问题,先试试看能不能走通。
服务端没毛病,但是前端怎么拿到结果?
fetch(pUrl, {
method: 'POST',
body: JSON.stringify({
test: 't-e-s-t'
}),
}).then((res)=>{
console.log(res)
})打印如下,有一个 ReadableSream,看起来,我们只需要把这个可读流的数据拿出来渲染就好了。 
ReadableStream - Web API | MDN
让大模型老师帮忙实现了一下,前端的代码如下,大致逻辑:
- reader 读到的数据都是二进制流数据,所以需要一个解码器 TextDecoder
- reader.read() 返回一个类似迭代器结果的 done, value 对象,永真循环
- 然后就是解析文本,把约定里的
\ndata:这些都给干了。
fetch(pUrl, {
method: 'POST',
body: JSON.stringify({
test: 't-e-s-t'
}),
}).then(async(res) => {
const reader = res.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = ''; // 用于拼接跨 chunk 的不完整行
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 将 Uint8Array 转成字符串
buffer += decoder.decode(value, { stream: true });
// 按换行符分割(SSE 每条消息以 \n\n 结尾,行内用 \n)
let lines = buffer.split('\n');
buffer = lines.pop(); // 保留最后一段不完整的行
for (let line of lines) {
line = line.trim();
// 忽略注释和空行
if (line.startsWith(':') || line === '') continue;
// 处理 data: 开头的消息
if (line.startsWith('data: ')) {
const data = line.slice(6); // 去掉 "data: "
try {
const json = JSON.parse(data);
console.log('收到消息:', json);
// 👉 在这里更新你的 UI 或触发回调
// yourOnMessageCallback(json);
} catch (e) {
console.log('收到文本消息:', data);
dom.textContent += data
}
}
// 可选:处理 event:、id:、retry: 等字段
// if (line.startsWith('event: ')) { ... }
// if (line.startsWith('id: ')) { ... }
}
}
console.log('SSE 流已关闭');
})这种情况难免让人觉得,那我还有必要遵循原生 EventSource 那一套约束规范吗?完全可以不用,我们可以自己定义自己的规则。
于是又问了大模型老师,发现了一种新格式 NDJSON(Newline Delimited JSON)
然后查了一下并读了一下相关的博客 你所不知道的ndJSON:序列化与管道流
这里又引出了序列化与管道流的概念 fetch一下需要await两次?【http玄学】_await response.json()
好啦,别扯远了,还是回到 SSE 上面,如果我们用这种 NDJSON ,直接用单个\n作为一次流的分隔,那一切都会很方便,我们先改一下 node 代码
app.post('/postSSE', (req, res) => {
console.log('body:', req.body);
res.header('Content-Type', 'text/event-stream')
res.header('Cache-Control', 'no-cache')
res.header('Connection', 'keep-alive')
const content = fs.readFileSync(path.join(__dirname, '/data.txt'), 'utf-8').split('')
let cur = 0
let timer = setInterval(() => {
res.write(JSON.stringify({
content: content[cur],
}) + '\n'); // 重点在这,也可以发多条消息,JSON格式并用\n分隔
cur++;
if (cur >= content.length) {
clearInterval(timer);
}
}, 100);
})于是前端的解码也就简化一些,我们只管拿到JSON就行
fetch(pUrl, {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({
test: 't-e-s-t'
}),
}).then(async (res) => {
const reader = res.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 将 Uint8Array 转成字符串
buffer += decoder.decode(value, { stream: true });
let lines = buffer.split('\n')
buffer = lines.pop()
lines.forEach(line => {
const data = JSON.parse(line)
console.log(data)
dom.textContent += data.content
})
}
})关于
buffer = lines.pop()保留“不完整的最后一行”,避免因 chunk 边界切断导致 JSON 解析失败。
假设服务端发送的是:
{"content":"Hello"}\n
{"content":"World"}\n
{"content":"流式很酷"}\n但在网络传输中,可能被拆成两个 chunk:
📦 Chunk 1 到达:
{"content":"Hello"}\n{"content":"W📦 Chunk 2 到达:
orld"}\n{"content":"流式很酷"}\n如果没有 buffer = lines.pop() ,直接 buffer.split('\n')通常会遇到不合法 JSON 报错。所以说本质原因。
❓我还有问题 为什么是 fetch ? XHR 不行?
XHR(XMLHttpRequest)不行,是因为它不支持“流式读取响应体”,而
fetch+Response.body.getReader()支持。 ❌ XHR 只能在响应完全结束后才拿到完整 body。
✅fetch的body是ReadableStream,可以边收边读 —— 这才是实现实时流的关键!
| 特性 | XHR | fetch |
|---|---|---|
| 响应体读取方式 | 必须等全部接收完,通过 xhr.responseText 一次性获取 | 可通过 res.body.getReader() 流式逐块读取 |
| 是否支持中途处理数据 | ❌ 不支持,必须等 onload | ✅ 支持,在 while(await reader.read()) 中实时处理 |
| 内存占用 | ❌ 大文件/长流会撑爆内存 | ✅ 低内存,边收边处理,GC 友好 |
| Header 和 Body 是否分离 | ❌ Header 到后仍要等 Body 完整 | ✅ Header 到即可开始读 Body 流 |
| 适合流式推送? | ❌ 完全不适合 | ✅ 原生支持 |
XHR 本质上是一个“全量加载”模型,不是“流式处理”模型,它的事件模型是:
xhr.onreadystatechange = function() {
if (xhr.readyState === 4) { // ← 只有状态 4(DONE)才表示“全部接收完毕”
console.log(xhr.responseText); // ← 此时才能拿到完整文本
}
}fetch 是现代 Promise-based API,设计时就考虑了流式场景:
fetch(url).then(res => {
const reader = res.body.getReader(); // ← 关键!拿到 ReadableStream 的 reader
return readStream(reader);
});
async function readStream(reader) {
while (true) {
const { done, value } = await reader.read(); // ← 每次读一个 chunk(Uint8Array)
if (done) break;
// 👉 实时处理 value,不用等全部数据!
}
}